
In modern database infrastructures, high availability (HA) is critical for ensuring that systems remain operational during node failures, maintenance, or other disruptions. PostgreSQL, while powerful, lacks built-in tools for easily achieving HA. This is where Patroni comes in as a PostgreSQL HA solution that manages replication and failover. Combined with ETCD as the distributed key-value store and HA Proxy as the load balancer, you can build a resilient, highly available PostgreSQL cluster.
This blog will walk through setting up a highly available PostgreSQL cluster using:
- 3 ETCD nodes (for distributed consensus)
- 2 Patroni nodes (for PostgreSQL replication and failover)
- HAProxy nodes (for load balancing)
- Keepalived (for VIP failover)
What is Patroni?
Patroni is an open-source tool designed to manage PostgreSQL high-availability (HA) clusters. It provides an automated and reliable solution for database failover and replication, ensuring that your PostgreSQL setup remains resilient and available in case of node failures. Patroni helps coordinate leader election, monitor cluster health, and promote standby nodes to the primary role when necessary. Its ease of configuration and integration with existing infrastructure makes it a popular choice for managing high-availability PostgreSQL environments.
What is ETCD?
ETCD is a distributed key-value store that plays a crucial role in achieving high availability (HA) for PostgreSQL clusters. As a reliable coordination service, ETCD is often used to store configuration data and coordinate cluster nodes in systems like Patroni. In a high-availability PostgreSQL setup, ETCD helps manage leader elections, monitor cluster health, and ensure data consistency across multiple database instances.
By providing a consensus-based mechanism, ETCD ensures that only one PostgreSQL node acts as the primary (leader) at any given time, while others function as replicas. In the event of a primary node failure, ETCD facilitates the automatic promotion of a replica to the primary role, minimizing downtime and ensuring continuous availability. Its simplicity, speed, and strong consistency make it a popular choice for managing distributed PostgreSQL clusters.
What is HA PROXY?
HA Proxy is a high-performance, open-source load balancer and proxy server that plays a key role in managing high availability (HA) in PostgreSQL clusters. In a high-availability setup, HAProxy is often used to route client connections to the correct PostgreSQL node, ensuring that read and write requests are directed appropriately.
HA Proxy helps manage traffic between the application and the database cluster by automatically directing connections to the primary node for write operations and to replica nodes for read operations. If the primary PostgreSQL instance fails, HA Proxy, in combination with tools like Patroni, can seamlessly reroute traffic to a newly promoted primary, ensuring minimal downtime.
With its fast and reliable performance, HA Proxy is widely used in PostgreSQL HA setups to balance load, handle failover, and provide a single-entry point for clients, thus improving both availability and scalability.
What is Keepalived?
Keepalived is an open-source routing software that enhances the availability of services by implementing high-availability features for systems like HAProxy, Keepalived enables multiple HAProxy instances to share a virtual IP address, ensuring that clients can always reach the load balancer, even if one instance fails.
In a typical setup, Keepalived monitors the health of the HAProxy nodes. If the primary HAProxy instance becomes unresponsive, Keepalived automatically transfers the virtual IP address to a standby instance, allowing continuous access to the backend services without manual intervention. This seamless failover capability enhances the resilience and uptime of applications, making Keepalived an essential component in high-availability architectures.
Architecture Overview
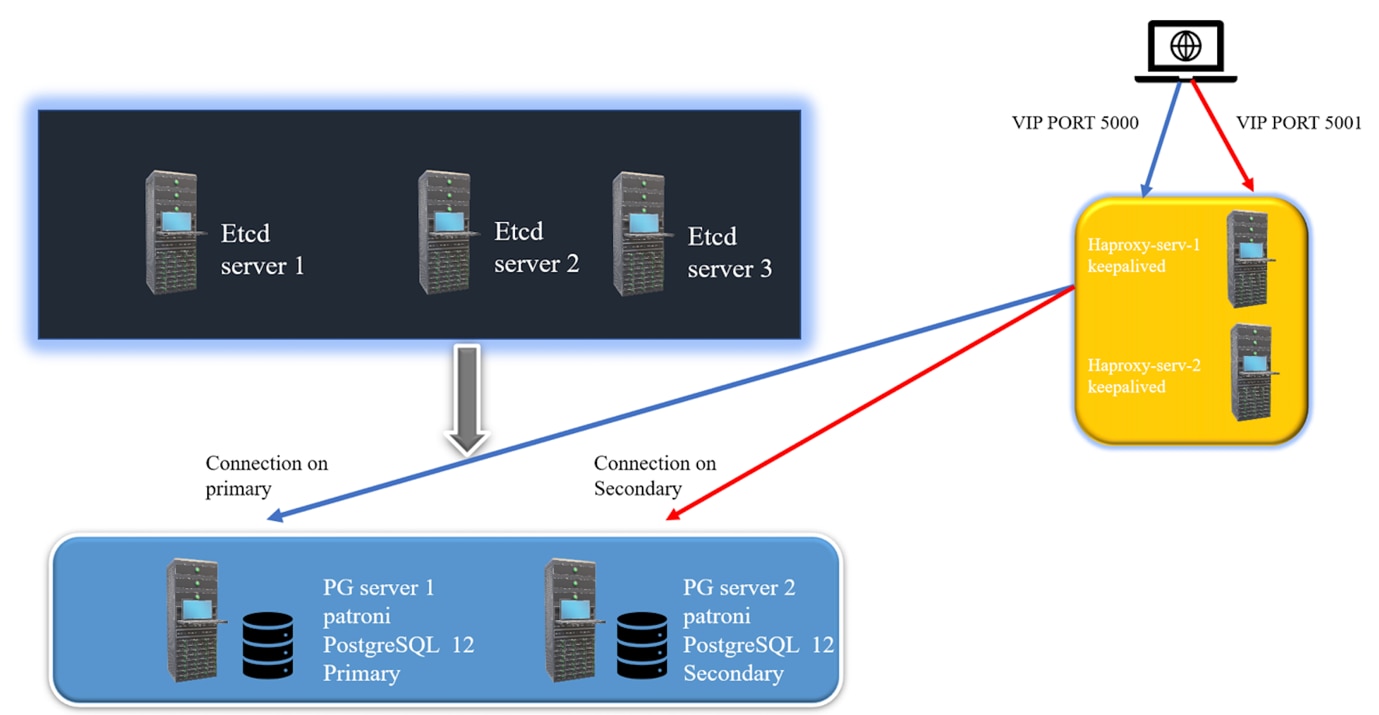
The architecture includes:
- 3 ETCD nodes for distributed configuration management and failover handling.
- Patroni nodes running PostgreSQL. Patroni ensures that one node acts as the leader while the other is a follower (replica).
- HAProxy nodes that will forward database traffic to the active Patroni leader, providing load balancing and failover.
- Keepalived runs on the HAProxy nodes to manage the VIP. If one HAProxy node fails, Keepalived automatically shifts the VIP to the surviving node.
Step by Step Demonstration for HA Setup:
Step 1: Setting Up a 3-node ETCD Cluster
The ETCD cluster will store the state of the Patroni cluster and help with leader election.
Install ETCD on all 3 ETCD nodes:

Configure ETCD on all three nodes:
On each node, modify the /etc/default/ETCD or /etc/ETCD/ETCD.conf file (depending on your OS).
On ETCD1, the configuration looks like this:
ETCD_NAME=node1
ETCD_DATA_DIR="/var/lib/ETCD"
ETCD_LISTEN_PEER_URLS="http://<node1-ip>:2380"
ETCD_LISTEN_CLIENT_URLS="http://<node1-ip>:2379,http://127.0.0.1:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://<node1-ip>:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://<node1-ip>:2379"
ETCD_INITIAL_CLUSTER="node1=http://<node1-ip>:2380,node2=http://<node2-ip>:2380,node3=http://<node3-ip>:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="ETCD-cluster-1"
Repeat the configuration on ETCD2 and ETCD3 by changing the ETCD_NAME and IPs accordingly.
Start and enable ETCD:
Step 2: Installing and Configuring Patroni
Install patroni on both servers

Configure Patroni (2 Nodes)
Each PostgreSQL node running Patroni needs a configuration file. Below is an example configuration for the first Patroni node. On both Patroni nodes, create a Patroni configuration file /etc/patroni.yml:
scope: pg_cluster
namespace: /service/
name: patroni1
restapi:
listen: 0.0.0.0:8008
connect_address: <patroni1_name>:8008
ETCD:
host: <ETCD_cluster_address>:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind:true
parameters:
wal_level: replica
hot_standby: "on"
wal_keep_segments: 8
max_wal_senders: 5
max_replication_slots: 5
synchronous_commit: "off"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin_pass
options:
- createrole
- createdb
postgresql:
listen: 0.0.0.0:5432
connect_address: <patroni1_name>:5432
data_dir: /var/lib/postgresql/12/main
bin_dir: /usr/lib/postgresql/12/bin
authentication:
replication:
username: replicator
password: repl_pass
superuser:
username: postgres
password: postgres_pass
parameters:
unix_socket_directories: '/var/run/postgresql'
On the second node, adjust name, connect_address, and any other node-specific details.
Start Patroni on both nodes:
sudo systemctl start patroni
Step 3 Setup HA Proxy
Install HA Proxy

Configure HAProxy (2 Nodes)
On both HAProxy nodes, edit /etc/haproxy/haproxy.cfg:
global
log /dev/log local0
log /dev/log local1 notice
maxconn 2000
user haproxy
group haproxy
defaults
log global
option redispatch
option tcplog
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
frontend postgresql
bind *:5432
default_backend postgresql-backend
backend postgresql-backend
balance roundrobin
option tcp-check
server postgresql1<patroni-node1-ip>:5432 check port 8008
server postgresql2 <patroni-node2-ip>:5432 check port 8008
Start HA PROXY
![]()
Step 4: Setup Keepalived (2 Nodes)
Install Keepalived

Step 4: Configure Keepalived
On both HAProxy nodes, edit /etc/keepalived/keepalived.conf to define a virtual IP (VIP) for failover.
Node1:
vrrp_script chk_haproxy {
script "pidof haproxy"
interval 2
weight 2
}
vrrp_instance VI_1 {
interface eth0
state MASTER
virtual_router_id 51
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass password123
}
virtual_ipaddress {
192.168.1.100
}
track_script {
chk_haproxy
}
}
Node 2:
vrrp_instance VI_1 {
interface eth0
state BACKUP
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass password123
}
virtual_ipaddress {
192.168.1.100
}
track_script {
chk_haproxy
}
}
Start and enable Keepalived:

Check Cluster with patronictl
patronictl list
+ Cluster: postgres-cluster (6958757123490168240) --------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+-----------+-------------+---------+---------+----+-----------+
| patroni1 | <patroni1_ip> | Leader | running | 3 | |
| patroni2 | <patroni2_ip> | Replica | running | 3 | 0 |
+-----------+-------------+---------+---------+----+-----------+
This confirms that the PostgreSQL cluster is running with one leader and one replica.
Conclusion
Setting up a highly available PostgreSQL cluster with ETCD, Patroni, HAProxy, and Keepalived ensures that your database remains online, even in the event of multiple node failures. This HA setup distributes responsibilities across various layers:
- ETCD ensures distributed consensus for Patroni.
- Patroni manages PostgreSQL replication and failover.
- HAProxy distributes traffic between the database nodes.
- Keepalived handles failover at the load-balancing layer with a floating VIP.
By following this guide, you can create a robust and resilient PostgreSQL environment capable of handling node failures with minimal downtime.





