
In the early days of data and analytics, traditional data warehouses on RDBMS databases served as the backbone for companies' analytical needs, providing a structured environment for storing and processing large volumes of structured data. However, as the volume and variety of data grew—encompassing semi-structured data like JSON files and unstructured data such as images and videos—traditional data warehouses began to show their limitations. Also, the sheer volume of this data (specially for ML use cases) strained traditional data warehouses. This is where the concept of the Data Lakehouse emerged, combining the best of both worlds. A Data Lakehouse integrates the flexibility and scalability of Data Lakes, which can accommodate all types of data, with the robust performance and analytics capabilities of data warehouses. Here I am explaining the Data Lakehouse implementation for one of our Financial Marketplace customers.
Internal Data Sources:
- Applications and Disbursal Data: Customer’s transaction data like loan, card, investment applications, approval data, disbursal details.
- Financial Aggregation Data: Semi-structured data from financial services like Account Aggregator and Perfios that contains customers bank statement details
External Data Sources:
- Data coming from partners like Adobe Analytics, Call centre data, Campaign response data. Mostly in semi structured, or structured format.
Architecture:
To build our Data Lakehouse, we implemented a medallion architecture, which organizes data into three distinct layers: bronze, silver, and gold. In this setup, AWS S3 serves as the storage solution for both the bronze and silver layers. The bronze layer ingests raw, unprocessed data, accommodating a variety of formats and structures.
The silver layer refines the data, transforming it into a more structured format suitable for analysis. Here, we leveraged our custom ETL framework, named "DRIFT," which utilizes AWS Glue for efficient processing of high-volume datasets.
For the gold layer, we opted for Amazon Redshift, utilizing Redshift Spectrum to seamlessly integrate the refined data from the silver layer. This allows us to perform advanced analytics and complex queries across both structured and semi-structured data efficiently.
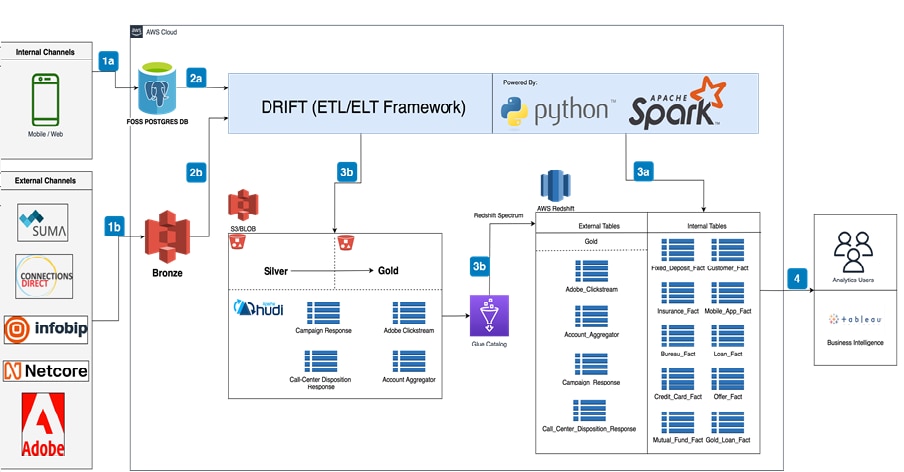
- 1a. Continuous replication from transaction system to ODS on postgres.
- 1b. Data from external sources, and unstructured internal sources into bronze
- 2b and 2c. Data processing by DRIFT – a highly configurable ETL framework
- 3a. Data loading into Redshift MPP database using DRIFT
- 3b. Data loading into Redshift Silver layer and gold layer using DRIFT
Hudi table format: We adopted the Hudi table format with Parquet files to enhance data management and performance. Hudi provides capabilities like incremental data processing, transaction support, ACID compatibility, time travel.
Parquet file format enables efficient storage and retrieval of large data and is supported by most big data technologies.
DRIFT ETL Framework – a configurable ETL framework developed at BTS using python for quickly creating new data pipelines to load data in Lakehouse.
Using DRIFT framework to setup jobs in Data Lakehouse involves simple configuration changes in four layers
- Column Mapping Layer:
To Map data from source to target layer for transformations and for basic schema validation. - SQL Layer:
Contains predefined SQL queries for filtering, joining, and aggregating data. These queries are applied in sequence to structure data for the Silver Layer, ensuring consistency across datasets. - TQL Layer (Transformation Query Language):
Adds flexibility for business logic and specific transformation rules not covered by SQL. TQL ensures that SQL scripts are executed in the right order under appropriate conditions. - YAML File:
Acts as the job configuration file, specifying input/output paths, transformation logic, SQL scripts, and metadata like partitioning and schema versions. The YAML must match the job name and provides critical processing instructions.
Gold layer using redshift spectrum: Gold layer is built on AWS redshift as combination of views on top of Redshift external tables (using Redshift spectrum) and physical summary/aggregated tables on Redshift. Aggregated summary tables store frequently queried and frequently aggregated data from multiple base gold tables.
Gold layer is used for data consumption for analytics or developing BI reports using Tableau.
Use cases: Here are some sample use cases we built on Data Lakehouse that require integration between application data and large external data sets
- SEO analytics:
Integrating large Adobe clickstream datasets with disbursement data from the application database to identify the URLs visited by organic traffic that led to the highest number of conversions. - Campaign effectiveness and governance:
Combining campaign response data with disbursal data to track campaign effectiveness as well as keeping governance on campaigns done against targeted customers. - Customer 360:
Combining customers internal and external data (demographic data, transaction data, product purchase history, offers data, campaign response data, clickstream data etc.) to provide a single 360-degree insight of customer for enhanced customer service, better personalized campaigns, and building analytical models for customer propensity scores.
Why Use Adobe Data Feed?
Our implementation for Data Lakehouse for Bajaj Markets leverages AWS services and our custom ETL framework DRIFT to enable integration of application data in data warehouse with data from external sources (and large/unstructured internal data sets) ensuring seamless access for advanced analytics.
Key Highlights:
- Unified Data Lakehouse
- Efficient ETL/ELT using our DRIFT Framework
- Scalable Infrastructure using s3 and redshift spectrum
References:





